
31 Aug
2020
31 Aug
'20
2:38 p.m.
This is a followup to my 8/6/20 e-mail to the CTPP-News listserv. Just two more after this
one. An “R” script is attached.
Example #2. More Complex Tidycensus examples: multiple years, multiple geographies,
multiple variables.
This is a more complex example of a script to “pull” select variables from the ACS using
my Census API key and the R package tidycensus.
Step #0. Always need to load the relevant packages/libraries when starting up a new
R-session. Otherwise, it won’t work.
# Step 0: Load relevant libraries into each R-session.
library(tidyverse)
library(tidycensus)
In this set of examples, I’m extracting single year ACS variables (2005-2018) for all
large (65,000+ population) places in the State of California.
# The get_acs function is run for each year of the single-year ACS data, from 2005 to
2018.
# Note that group quarters data was not collected in 2005, but started in 2006.
# Note the "_05_" included in the variable name in the first data
"pull". That's a # # mnemonic device that tells us it's for the year
2005.
# Example 2.1 through 2.14: Run get_acs for large California Places, 2005-2018
# Example 2.15: Merge together data frames into a VERY wide database...lots
of columns!
# Example 2.16: Merge in a file of Large San Francisco Bay Area places, and
subset file.
#-------------------------------------------------------------------------------
place05 <- get_acs(survey="acs1", year=2005, geography = "place",
state = "CA",
show_call = TRUE, output="wide",
variables = c(TotalPop_05_ = "B06001_001", # Total Population
Med_HHInc_05_ = "B19013_001", # Median Household Income
Agg_HHInc_05_ = "B19025_001", # Aggregate Household Income
HHldPop_05_ = "B11002_001", # Population in Households
Househlds_05_ = "B25003_001", # Total Households
Owner_OccDU_05_= "B25003_002", # Owner-Occupied Dwelling
Units
Rent_OccDU_05_ = "B25003_003", # Renter-Occupied Dwelling
Units
Med_HHVal_05_ = "B25077_001")) # Median Value of Owner-Occ
DUs
place05$Avg_HHSize_05 <- place05$HHldPop_05_E / place05$Househlds_05_E
place05$MeanHHInc_05 <- place05$Agg_HHInc_05_E / place05$Househlds_05_E
#------------------------------------------------------------------------------------
place06 <- get_acs(survey="acs1", year=2006, geography = "place",
state = "CA",
show_call = TRUE, output="wide",
variables = c(TotalPop_06_ = "B06001_001", # Total Population
Med_HHInc_06_ = "B19013_001", # Median Household Income
Agg_HHInc_06_ = "B19025_001", # Aggregate Household Income
HHldPop_06_ = "B11002_001", # Population in Households
Househlds_06_ = "B25003_001", # Total Households
Owner_OccDU_06_= "B25003_002", # Owner-Occupied Dwelling
Units
Rent_OccDU_06_ = "B25003_003", # Renter-Occupied Dwelling
Units
Med_HHVal_06_ = "B25077_001")) # Median Value of Owner-Occ
DUs
place06$Avg_HHSize_06 <- place06$HHldPop_06_E / place06$Househlds_06_E
place06$MeanHHInc_06 <- place06$Agg_HHInc_06_E / place06$Househlds_06_E
#------------------------------------------------------------------------------------
These sets of codes are repeated for each single year ACS of interest, say for 2005
through 2018. Smarter “R” programmers will be able to tell me about “do loops” to make
this process more efficient with magical wild cards.
The following step merges the data frames using the GEOID/NAME variables. This create a
very “wide” database. One record per geography, and each column representing the
variable/year combinations.
The “merge” function in “R” allows only two data frames to be joined by common columns at
a time. I have yet to find a “R” function that allows me to merge all of the data frames
at once.
#####################################################################################
# Example 2.15: Merge together data frames into a VERY wide database...lots of columns!
# Merge the dataframes, adding a year in each step. All=TRUE is needed if # of places is
different.
#
# (R-language newbie script...There are probably more terse/exotic ways of doing this!)
place0506 <- merge(place05, place06, by = c('GEOID','NAME'),
all=TRUE)
place0507 <- merge(place0506,place07, by = c('GEOID','NAME'),
all=TRUE)
place0508 <- merge(place0507,place08, by = c('GEOID','NAME'),
all=TRUE)
place0509 <- merge(place0508,place09, by = c('GEOID','NAME'),
all=TRUE)
place0510 <- merge(place0509,place10, by = c('GEOID','NAME'),
all=TRUE)
place0511 <- merge(place0510,place11, by = c('GEOID','NAME'),
all=TRUE)
place0512 <- merge(place0511,place12, by = c('GEOID','NAME'),
all=TRUE)
place0513 <- merge(place0512,place13, by = c('GEOID','NAME'),
all=TRUE)
place0514 <- merge(place0513,place14, by = c('GEOID','NAME'),
all=TRUE)
place0515 <- merge(place0514,place15, by = c('GEOID','NAME'),
all=TRUE)
place0516 <- merge(place0515,place16, by = c('GEOID','NAME'),
all=TRUE)
place0517 <- merge(place0516,place17, by = c('GEOID','NAME'),
all=TRUE)
place0518 <- merge(place0517,place18, by = c('GEOID','NAME'),
all=TRUE)
place_all <- place0518
View(place_all)
Sometimes you want to create smaller data frames with just a select number of columns.
Here’s a good approach for that.
# The following functions output useful lists to the R-studio console which can then be
edited
names(place_all)
dput(names(place_all)) # most useful for subsetting variables
# The purpose here is to re-order and select variables into a much more compact
# database, for eventual exporting into a CSV file, and then into Excel for finishing
touches.
selvars <- c("GEOID", "NAME",
"TotalPop_05_E", "TotalPop_06_E",
"TotalPop_07_E", "TotalPop_08_E",
"TotalPop_09_E", "TotalPop_10_E",
"TotalPop_11_E", "TotalPop_12_E",
"TotalPop_13_E", "TotalPop_14_E",
"TotalPop_15_E", "TotalPop_16_E",
"TotalPop_17_E", "TotalPop_18_E")
# note the brackets for outputing new data frame from previous data frame....
place_all2 <- place_all[selvars]
# View the Selected Variables Table
View(place_all2)
# Set directory for exported data files, MacOS directory style
setwd("~/Desktop/tidycensus_work/output")
# Export the data frames to CSV files, for importing to Excel, and applying finishing
touches
write.csv(place_all2,"ACS_AllYears_TotalPop_Calif_Places.csv")
write.csv(place_all, "ACS_AllYears_BaseVar_Calif_Places.csv")
In this last example, I’m reading in a file of large places in the Bay Area (manually
derived from the CSV file created previous) in order to subset Bay Area “large places”
from State of California “large places”.
#####################################################################################
# Example 2.16: Merge in a file of Large San Francisco Bay Area places, and subset file.
# Read in a file with the Large SF Bay Area Places, > 65,000 population
# and merge with the All Large California Places
bayplace <- read.csv("BayArea_Places_65K.csv")
Bayplace1 <- merge(bayplace,place_all, by = c('NAME'))
Bayplace2 <- merge(bayplace,place_all2, by = c('NAME'))
write.csv(Bayplace1,"ACS_AllYears_BaseVar_BayArea_Places.csv")
write.csv(Bayplace2,"ACS_AllYears_TotalPop_BayArea_Places.csv")
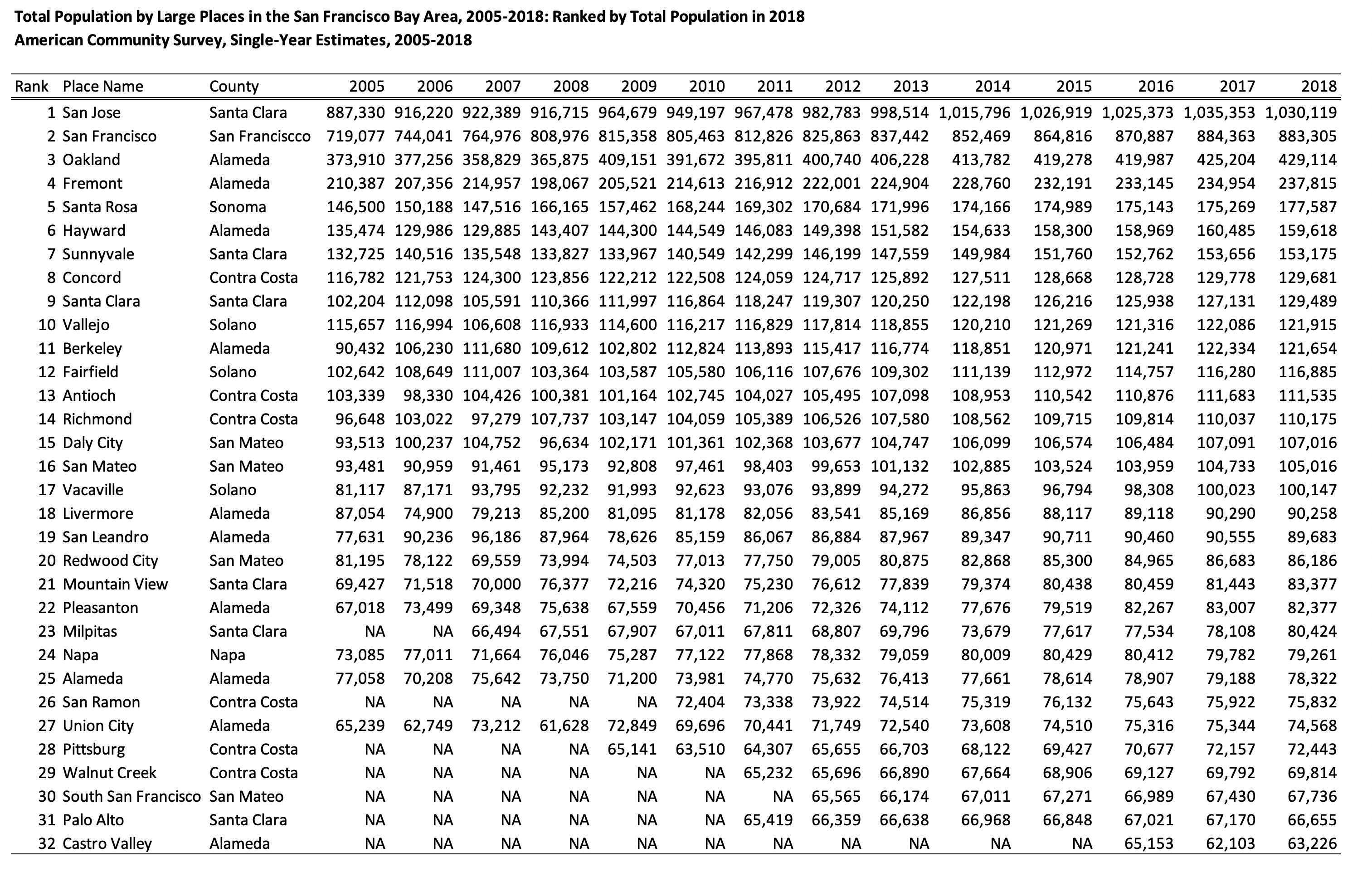
Here’s a screenshot of a summary table showing total population in large places in the San
Francisco Bay Area, 2005-2018. (It’s a big table, better viewed in landscape mode, letter
size!)
This concludes Example #2: “multiple geographies / multiple years/ multiple variables”
with only one record (row) per each geography.
{kind=link}
2011
days inactive
2011
days old
0 comments
1 participants
participants (1)
-
 Charles Purvis
Charles Purvis