
16 Sep
2020
16 Sep
'20
2:33 p.m.
Can I get a list of places within my multi-county region? Yes, but it takes a little
work!
Finding Places within Counties for Your State and Region.
This is an “R” script which uses readily downloadable files from the decennial census to
build a file of places within counties within states. This can then be subsetted to
extract lists of places within a one-county or multi-county region. The following examples
used 2010 Census data for the states of California, Texas, and New York, and can
hopefully be easily adapted once the 2020 Census data becomes available spring 2021.
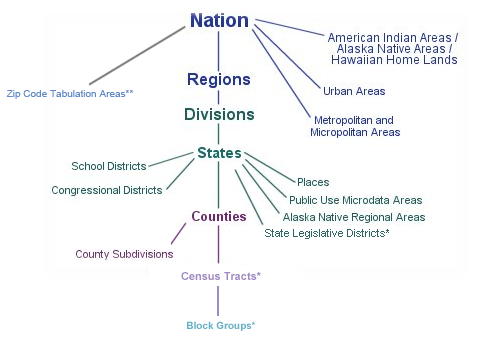
The standard Census geography hierarchy diagram shows that “places” are below “states.”
“Places” are NOT below “County” geographic levels. This is because there are some “places”
in the United States that straddle two-or-more counties! This is an inconvenience if the
analyst is interested in, say, the population characteristics of all places (cities,
census designated places) within a one-county or multi-county region.
A simple, creative way to find places-within-counties is to use GIS software to layer both
county boundaries and place boundaries to select your places of interest. But this process
doesn’t say anything about the population characteristics of places that potentially
straddle two-or-more counties!
But there are two Census “summary levels” that can be used to clearly identify
places-within-counties: summary level 160 (state-place); and summary level 155
(state-place-county). The #160 summary level is the more commonly used of the two. The
#155 summary level is pretty much a secret summary level only used by curious census data
wonks.
The two summary levels, combined, provide an accurate database of places-within-counties,
including lists of places that straddle two-or-more counties.
The simplest approach is to download the available PL 94-171 “Redistricting File” for the
US state of interest. Here’s the link to the Census 2010 Redistricting Files:
https://www2.census.gov/census_2010/redistricting_file--pl_94-171/
<https://www2.census.gov/census_2010/redistricting_file--pl_94-171/>
What is important is the “geographic header” file that includes all geographic summary
levels of interest, including summary levels 155 and 160.
The following example extracts summary level 155 and 160 data for places in California,
from Summary File #1 (SF1), though the PL 94-171 geographic header file is identical!
The filename “cageo2010.sf1” means “California” + “Geographic” + “2010” from “SF1”
This is a good example of building an “R” data frame from a fixed-format data file.
###########################################################################
## Extract the California Place Names and their Counties from the
## 2010 Decennial Census master geographic file, California, SF #1
###########################################################################
# install.packages("tidyverse")
# install.packages("dplyr")
library(dplyr)
setwd("~/Desktop/tidycensus_work/output")
setwd("~/Desktop/Census/2010_Census/ca2010.sf1")
# setwd("~/Desktop/ca2010.sf1")
x <- readLines(con="cageo2010.sf1") # Very large fixed format file, 843,287
observations for Calif
CalGeo <- data.frame(# fileid = substr(x, 1, 6),
# stusab = substr(x, 7, 8),
sumlev = substr(x, 9, 11),
# geocomp= substr(x, 12, 13),
state = substr(x, 28, 29),
county = substr(x, 30, 32),
place = substr(x, 46, 50),
# tract = substr(x, 55, 60),
# blkgrp = substr(x, 61, 61),
# block = substr(x, 62, 65),
arealand=substr(x, 199, 212),
areawatr=substr(x, 213, 226),
name = substr(x, 227, 316),
pop100 = substr(x, 319, 327),
hu100 = substr(x, 328, 336))
CalGeo$GEOID <- paste(CalGeo$state,CalGeo$place,sep="")
The following statements extract all summary level 155 and 160 records from the master
geo-header file. The two files are then merge by the variables “state” and “place” and
variables are renamed to something more recognizable. Note that if the variable names are
the same in the merged data frames, “R” uses a convention of “variablename.x” for the
first data frame and “variablename.y” for the second data frame used in the merge.
sumlev155 <- subset(CalGeo, sumlev == 155) # state-place-county summary level
sumlev160 <- subset(CalGeo, sumlev == 160) # state-place summary level
coplace1 <- merge(sumlev155, sumlev160, by = c('state','place'),
all=TRUE)
coplace2 <- dplyr::rename(coplace1, county_name = name.x, # name is eg "Contra
Costa County (part)"
place_name = name.y, # name is eg "Acalanes Ridge
CDP"
county = county.x,
GEOID = GEOID.x)
The following statements are intended to identify places that straddle two-or-more
counties in the state. In California (in 2010) we had four places that each straddle two
counties, for a total of eight place-county records! These four place are Aromas
(Monterey/San Benito Counties), Kingvale (Nevada/Place Counties), Kirkwood (Alpine, Amador
Counties) and Tahoma (El Dorado/Place Counties).
# Extra places that straddle two-or-more counties.
# pop100.x = 2010 population count for, perhaps, part of the place (sumlev=155)
# pop100.y = 2010 population count for the FULL place (sumlev=160)
# This yields 4 places that straddle 2 counties, each, for 8 records in this file.
splittown <- subset(coplace2, pop100.x < pop100.y)
View(splittown)
And lastly, I wanted to extract the places within the nine-county San Francisco Bay Area.
This is probably the simplest script for this extraction.
# Subset the Bay Area places from the SUMLEV=155/160 file
BayArea <- subset(coplace2, county== "001" | county=="013" |
county=="041" |
county=="055" | county=="075" | county=="081" |
county=="085" | county=="095" |
county=="097" )
# c(1,13,41,55,75,81,85,95,97)
Of course, write out the data frames to CSV files for further analysis.
setwd("~/Desktop/tidycensus_work/output")
write.csv(BayArea,"Census2010_BayArea_Places.csv")
write.csv(coplace2,"Census2010_California_Places.csv")
Let’s check Texas!
Just to check this procedure, I downloaded the PL 94-171 data files for the State of
Texas. The geo-header file for Texas was even larger than California (n=1,158,742 records
in Texas, n=843,287 records in California!)
Texas has 1,752 places (sumlev=160) and 1,934 place-county parts (sumlev=155). Upon
inspection, there are places in Texas (Dallas!) that straddle five counties. That caught
me by surprise!
The population-based split procedure for California (subset(coplace2, pop100.x <
pop100.y)) didn’t work for Texas since there are a few place-county parts in Texas with
zero population. I found that “arealand” works just fine for Texas. The following code
works for Texas:
# Extra places that straddle two-or-more counties.
# pop100.x = 2010 population count for, perhaps, part of the place (sumlev=155)
# pop100.y = 2010 population count for the FULL place (sumlev=160)
# Find the Texas places straddling two-or-more counties
splittown <- subset(coplace2, pop100.x < pop100.y)
View(splittown)
# This works better for Texas, since there are a few place-county parts with zero
population,
# and 100 percent of population in the other place-county part.
splittown2 <- subset(coplace2, arealand.x < arealand.y)
View(splittown2)
That’s as far as I’ve carried the Texas example, since I’m not on the lookout for a master
national list of places split by county boundaries! Maybe this is something that the
Census Bureau Geography Division has ready access to?
Let’s check New York!
This process also works for the State of New York. It’s still best to use the “AREALAND”
differences, sumlev=155 versus sumlev=160, to find places that straddle
two-or-more-counties (or boroughs in the case of New York City).
Yes, the City of New York straddles/encompasses five boroughs/counties. And there are 13
other places in New York State that straddle two counties: Almond, Attica, Brewerton,
Bridgeport, Deposit, Dodgeville, Earlville, Geneva, Gowanda, Keeseville, Peach Lake,
Rushville, and Saranac Lake.
These are “R” scripts that don’t use “tidycensus” but are clean methods for answering
such a simple question as “what are the census places within my multi-county region?”
{kind=link}
1995
days inactive
1995
days old
0 comments
1 participants
participants (1)
-
 Charles Purvis
Charles Purvis